
Ever since I saw Ilmenit’s fantiastic, highly artistic intro Mona I have been entertaining the thought of making an Atari ST port. Here’s how it came into existence.
Prerequisites
This article will make more sense when the following are met:
- Knoweledge of 68000 assembly programming.
- An understanding of the ST hardware (bitplanes, system calls, screen format etc)
- In order to understand a few things in this article better, you are invited to open a copy of The Atari Compendium as it will be referenced a few times. Here is an online copy.
- All timestamps are CET+2.
The header controversy
But first, let’s address the elephant in the room.
The file size of the executable is 288 bytes. That’s 32 whole bytes over the limit and there are people who will call this “cheating”, so this should be disqualified.
This talk comes up in demoscene forums, usually from people whose favorite platforms’ binary formats either have no header at all (so their prorgams load at a fixed address) or a very tiny one that usually just has the load address. Of course these will very graciously add the header size to the total file size, so platforms like the Atari ST (and compatibles) are massive cheats.
First of all, saving 2 bytes at most is vastly different to saving 32 bytes in size limited competitions (64, 128, 256 bytes). Secondly, the aforementioned platforms with small headers can afford to have small headers since the load and run address is determined at assembly time. Also, if one knows the load address during assembly time, a large avenue of optimisations is available to them.
The Atari ST (and compatibles) program format is relocatable executable, which means that the program is not ready to run when loaded to memory. The system has to perform a pass to fix up any absolute addresses (which are not known during build time) and then jump to the program. This means that in addition to the header, a table of fixups has to be embedded at the end of the binary. (For further info you can take a look at the Atari Compendium, section 2.9, “GEMDOS Processes”)
Having said all that, are the Atari ST people the only dirty cheaters? (because hey, people do seem to gang up against Atari when it is mentioned for some reason. I guess people never change)
Let’s have a short look at the latest 256 bytes intro submitted to Pouet (at the time of writing) on ZX spectrum: Just Snow by Errorsoft. Note that I did not pick this on purpose, nor I have something against the author. This is merely to illustrate a point.
Inside the download .zip file there is a 369 byte .tap file. That’s probably ok though, it is most likely a container format, right?
So let’s open it with ZX-Preview so we can have a quick look inside it.
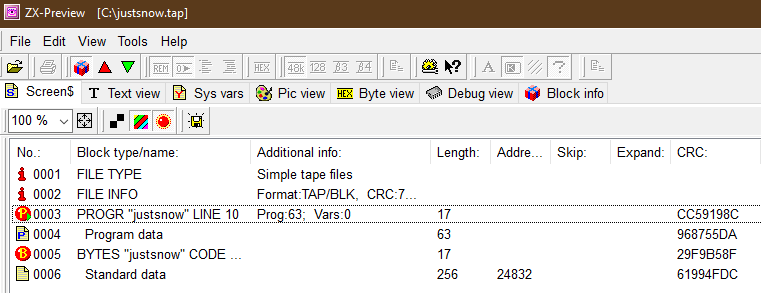
So entries 0001, 0002 and 0003 seem to be innocent enough, seem to be decribing what is going to be loaded etc. And there’s 0006 that’s exactly 256 bytes so that’s obviously the program itself. All fine. But why are there two blocks of data, 0004 and 0006? And what’s that 0005 “BYTES” all about? Let’s click on 0004 and see what we get.
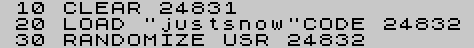
What the… why is there a Basic program in there? Did we just see a…. custom loader in there? And it’s not part of the payload? Is that even allowed?
So yes, it seems like our ZX friends simply threw away the rules (if there were any to begin with) and took advantage of the full 256 byte limit for code by just having a 2 stage loading process. This is not intended to be finger pointing, it’s just meant to illustrate what other platforms do.
So, to get back to our case, this opens a whole range of possibilities: we could even go as far as to make a standarised loader for size limited programs so we can “legally” distribute it with our releases. Or, hell, we can make our own custom version of TOS that introduces a new file format that hardcodes the load/run address to a fixed value. The sky’s the limit here!
…or we can simply just continue to do what we do now, release everything under a 256+32=288 binary file and explain what’s happening inside the README.
To conclude: yes, technically this is against the rules (as 288>256 if we accept basic maths). But were the rules made under consideration of the header size of different platforms? Methinks not.
General topics
To help people understand a few things about the system better, I decided to analyse a few topics before presenting the code in itself.
Set screen buffer and resolution
Ideally when our program starts we want to have a nice clear screen buffer. Sadly when a program is started from the GEM desktop, it is expected to be a well behaving application. Exactly what we don’t want! There are a few options to rectify this:
- clear the screen ourselves (and set resolution as a bonus)
- start the application as a .TOS program (i.e. change the extension from .PRG to .TOS). This tells GEM to shut itself down and start the program on a blank screen. Close to ideal but we also get a blinking cursor at the top left of the screen. Annoying!
- demand that the program starts from the AUTO folder. This way we get a clear screen (if nothing in the AUTO folder prints something before we get to run) and no blinking cursor in sight. However this is usually forbidden by the competition rules, and anyway: who wastes a whole disk (or hard disk for that matter) just to run a bytetro?
Some code to clear the screen and set ST Low resolution follows:
clr.w -(SP) ; Set ST Low
move.l #-1,-(SP) ; Don't change physical screen pointer
move.l (SP),-(SP) ; Same goes for logical
move.w #5,-(SP) ; Function number
trap #14 ; Call XBIOS
lea 12(SP),SP ; Adjust stack
Not brilliant (this wastes 20 bytes) but as a first step it’ll do.
How to plot pixels on screen
If we were to write our own pixel plot routine we would have ended up with a lot of bytes. At miminum we’d need to:
- calulate the offset to screen to plot
- calculate the bit from the bitplane to change
- colour selection, i.e. figure out which bitplanes we’d need to change
- clear the old pixel values - because we will be writing on top of other brushes we can’t assume it’ll be zeroed out
- actually set the pixels for the desired colour
That by itself would take a good chunk of our 64 instruction budget. And we didn’t even touch multiple resolution support! (not that it’s required, just nice to have). So instead we can toss away all this complexity and use the system routines. Yes, they’re probably orders of magnitudes slower, but look at the actual code required to plot a pixel on screen:
dc.w $A000 ; Initialise (get variable table in a0)
move.l a0,a5 ; Line-A variables in a5
move.l #col,8(A5) ; Set intin
move.l #coords,12(A5) ; Set ptsin
dc.w $A001 ; Plot the pixel
col: dc.w 1
coords: dc.w 10,10
So: just initialise Line-A, set colour number and coordinates, and jump to the draw function. Plus resolution independence as a bonus!
One thing to note here is that any Line-A call will trash registers a0, a1, a2, d0, d1 and d2. So by using this we effectively lose six registers (unless we save and restore registers before the calls, but that wastes even more bytes).
Of course this is still a huge amount of bytes (24 if you’re counting), but we can revisit that later.
Regression “suite”
A positive side effect of making the first version in GFA 32 is that I could export all the coordinate pairs into a binary file. That way I could add the same functionality to my 68000 code and then byte compare the two files. This kept me in line and avoided diversions of the original image as the code transformed into something totally different from the first reference version.
This sounds like a chore but in practice it was very easy to set up. For starters, this only kicked in when I wanted to, so I used conditional assembly:
dump EQU 0 ;save "dataset",.dataset,^a4
This also has the usage command in the comment. While inside Bugaboo I’d type the command and it’d dump out the file. a4 pointed to the address of the last written coordinate pair.
Some setup was necessary at the start of the code:
IF dump
lea dataset,A4
ENDC
And then some code was executed right before each pixel was plotted. This would save out the coordinate and colour, so all the things that could change.
IF dump
movem.w D2/D5,(A4)
move.l D6,4(A4)
addq.l #8,A4
ENDC
Finally a large enough buffer was allocated in the BSS to store the data:
IF dump
dataset:
DS.L 65535
DS.L 65535
DS.L 65535
DS.L 65535
DS.L 65535
ENDC
In practice there were very few times (less than 5 for sure) that this check asserted. But it was worthwhile to have it around as judging the image by eye can be misleading (especially a few hours into the project!).
A short explanation of the algorithm
Ilmenit himself has written a short explanation on Pouet, here are the relevant bits from that post:
- The seeds were found with iterative brute-force approach.
- Each brush stroke is a layer which covers the previous one, therefore is mostly independent in calculations.
- For each layer there is a 16bit seed to be found that generates the best picture possible.
In other words: imagine that you have a line that can move only in cardinal directions and can change direction in a controlled (i.e. pseudo random) fashion. Finally, we’re going to wrap its movement inside a 128x128 box, so anything outside the limits gets wrapped around. Here is such a line:

Now, what if we had 64 and the first ones we drew were longer in size than the last ones? Using the longer ones we’d be able to fill larger areas and maybe even let them wander off in areas we wouldn’t want. It doesn’t matter much because the areas we wouldn’t normally want to be drawn will be written over by later lines anyway. Then, the shorter lines at the end could be used to bring out more details in the image, since they wouldn’t be able to travel very far and off course (also, if we choose the pseudorandom seeds properly, they won’t have a chance to do so).
The result, in slow motion, can be seen here:
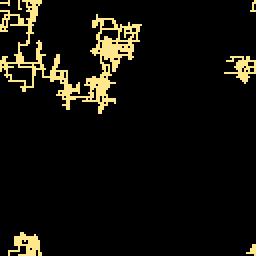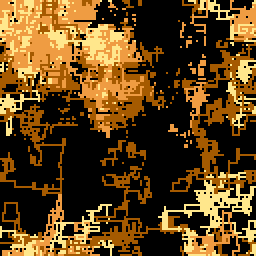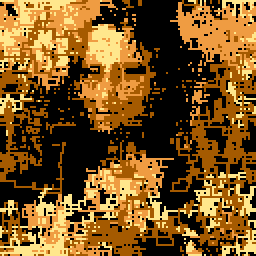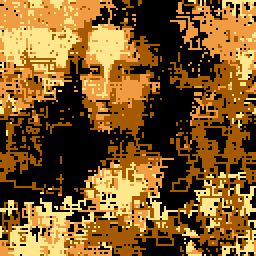
Another explanation is available in code golf.
May 28 2020, #atariscne
(Note: all dates and events are accurate and in sequence to the best of my memory. There might be some errors or things out of order here and there, but that’s the closest you’re going to get)
21:31 < ggn@> mona st version
21:32 < evl@> that rocked on the xl
During a discussion on IRC about an upcoming size coding compo (Sommarhack 2020) it was evl’s comment that sort of made me actually go ahead and attempt a port.
Some reasons that made me be on the fence for 6 years were:
- Boredom (never understated)
- The fact that a lot of 6502 opcodes are single byte, which means potentially bigger programs can fit inside the same size with properly chosen opcodes. In contrast the 68000 starts with 2 bytes per instruction minimum
- Fear that I’ll fail miserably
However, a quick refresher at the source code made me feel more optimistic. As discussed above, the table that contains the brush info is 128 bytes of uncompressable data (+4 if you count the initial seed value). This means that the code would have to be about 128 bytes, so 128 instructions max. Squeezing 128 to 64 sounds a lot better than squeezing 256 down to 128!
Looking at the original’s assembly source code made me realise another thing: the whole intro is more or less 53 instructions (because not all 6502 instructions can be encoded in a single byte). A-ha! So maybe there is a chance after all!
May 29 2020
Since the codegolf page has a pseudo code version of the original 6502 code I could use that as a basis to start. This also meant that I didn’t have to spend time reading at the original code and misinterpet it (I am not that fluent in 6502 assembly). So, a quick prototype was written in good old GFA 32 just for reference.
May 28 2020, around 21:00 to May 29 2020 17:25
The first version of the intro was written (in GFA32 and 68000 assembly language). Here it is in verbatim (some profanity might have been omitted):
; Started 28th May 2020 around 21:00
; Almost worked the first time! (without size optimising)
; (it basically worked but line-a was clobbering the x coord, d'oh!)
; First "yes it works, shut up" version in 29th May 2020 17:25 - 302 bytes
;d3=dir=assumed 0
dump EQU 1 ;save "dataset",.dataset,^a4
lowres EQU 1
IF lowres
clr.w -(SP)
move.l #-1,-(SP)
move.l (SP),-(SP)
move.w #5,-(SP)
trap #14
lea 12(SP),SP
ENDC
IF dump
lea dataset,A4
ENDC
; if we switch to super mode, this can be replaced by move.l #pal,$45a.w
pea pal(PC)
move.w #6,-(SP)
trap #14
linea #0 [ Init ]
movea.l A0,A5 ;pointer to linea variables
move.l #col,8(A5)
move.l #coords,12(A5)
; Who even adjusts the stack in 256 byte intros?
pea clrscr(PC)
move.w #9,-(SP)
trap #1
move.l #$7EC80000,D6 ;seed
moveq #63,D7
lea brush(PC),A6
outer_loop: move.w (A6)+,D6
move.b D6,D2 ;bx
move.w D6,D5
lsr.w #8,D5 ;by
move.w D7,D4
addq.w #1,D4
lsl.w #5,D4
subq.w #1,D4 ;inner loop counter
inner_loop: add.l D6,D6 ;test seed for carry
bge.s carry_clear
eori.l #$04C11DB7,D6
move.b D6,D3 ;load seed
carry_clear:
and.b #$82,D3
bne.s no_00
addq.w #1,D5
no_00:
cmp.b #$02,D3
bne.s no_02
addq.w #1,D2
no_02:
cmp.b #$80,D3
bne.s no_80
subq.w #1,D5
no_80:
cmp.b #$82,D3
bne.s no_82
subq.w #1,D2
no_82:
andi.w #$7F,D2
andi.w #$7F,D5
movem.w D2/D5,coords
IF dump
movem.w D2/D5,(A4)
move.l D6,4(A4)
addq.l #8,A4
ENDC
movem.l D0-A6,-(SP)
linea #1 [ Putpix ]
movem.l (SP)+,D0-A6
dbra D4,inner_loop
addq.w #1,col
andi.w #3,col
dbra D7,outer_loop
illegal
brush: DC.W $030A,$37BE,$2F9B,$072B,$0E3C,$F59B,$8A91,$1B0B
DC.W $0EBD,$9378,$B83E,$B05A,$70B5,$0280,$D0B1,$9CD2
DC.W $2093,$209C,$3D11,$26D6,$DF19,$97F5,$90A3,$A347
DC.W $8AF7,$0859,$29AD,$A32C,$7DFC,$0D7D,$D57A,$3051
DC.W $D431,$542B,$B242,$B114,$8A96,$2914,$B0F1,$532C
DC.W $0413,$0A09,$3EBB,$E916,$1877,$B8E2,$AC72,$80C7
DC.W $5240,$8D3C,$3EAF,$AD63,$1E14,$B23D,$238F,$C07B
DC.W $AF9D,$312E,$96CE,$25A7,$9E37,$2C44,$2BB9,$2139
clrscr: DC.B 27,"E" ;the zero termination happens at the palette
; Array(0xFFE289, 0xE99E45, 0xA55A00, 0x000000) As Int
pal:
; DC.W 0,$0FE9,$0FA4,$0A60 non-ste order
DC.W 0,$0F74,$0FC9,$0CA0 ;ste order (probably!)
col: DC.W 1
BSS
DS.W 12 ;pad for the palette
coords: DS.W 2
dataset:
DS.L 65535
DS.L 65535
DS.L 65535
DS.L 65535
DS.L 65535
END
Nothing terribly exciting with this version. This was just a transliteration of the pseudo code just to get a reading on the file size. As it is mentioned in the comments the code size is 302 bytes (359 if resolution setting/screen clearing is also assembled). The code blocks are explained below (with any interesting information):
- There is optional code for resolution and screen clearing using a XBIOS 5 call as described in [Set screen buffer and resolution] above
- Dump code is in place as discussed in Regression “suite” above
- Palette is set using a XBIOS 6 call. Our image is 4 colours so in theory we could only bother with setting those 4 colours. The system call though expects a 32 byte chunk of RAM which will copy to the palette registers. In order to save space, an old trick is used: The actual palette values we care are placed at the very end of the TEXT section and the remaining 12 at the beginning of the BSS. Since our DATA section is 0 bytes and all sections are in contigious RAM, the result will be our 4 palette values and 12 zeroed ones, courtesy of the OS. A final comment here: if we were really starving for bytes we could have also moved the background colour value (which contains a 0) to the BSS. This way we’d gain 2 bytes but the backgrond wouldn’t be black. Also we’d need to start at a different colour. This was left out and would only be used if things got really desperate.
- The initialisation of Line-A is pretty much as mentioned above in How to plot pixels on screen. It is not very good as it uses relocatable symbols (col and coords) which means that the assembler would have to generate relocation information, thus increasing the file size. This also would make the maths not make sense: 302+32=334 bytes, but the actual file is 339 bytes due to relocation information. Oops!
- The initial idea to clear the screen would be to use a GEMDOS call (#9) to print the VT52 command to clear the screen (ESC+E). Notice the cute detail of not null terminating the string because we make sure that a zero follows it: the background palette value!
- As mentioned in the comment, we can get away with not adjusting the stack after the GEMDOS call because we do not intend to exit from the intro cleanly (pushing reset would be required).
- Next comes the actual draw loop.
- It’s a dual nested for, one to count the number of brushes and one to draw each brush.
- The initial seed ($7EC80000) is loaded outside the loops
- The initial colour is #1 (i.e. not the background colour)
- In the outer loop the initial coordinates of the brush are actually the brush seed loaded.
- For each pixel of the current brush the seed register d6 is shifted left once, and if there’s a carry overflow we exclusive OR the register with the fixed value of $04C11DB7.
- Bits #1 and #7 of the shift register are used as a selector for movement. Out of the 4 possible values the following apply:
- $00: down
- $02: right
- $80: up
- $82: left
- The coordinates are then bound inside (0,0)-(127,127) and stored
- Line-A is called to plot the pixel
- When each brush is drawn the colour is cycled (1, 2, 3, 0, 1…)
- Since this is still a debug build, the execution is stop by an
illegalinstrction, so we can drop to the debugger.
On one hand this version showed promise; there is apparent fat to cut here and there. On the other hand: would this be enough?
May 29 2020, 18:47 - 294 bytes
A few size optimisation ideas are applied.
First and foremost is the col variable. Our problem is that we require that the first colour we use is #1, so we need a constant of 1. But, by simply moving the addq.w #1,col/andi.w #3,col at the start of the outer loop we can place col in any point outside the inner/outer loop (for example the init code) which has its lower 2 bits set to 0. By placing the colour increase at the start of the outer loop, this will then read the old data, increse it by one and mask off the upper bits. So there we have it, we can now start with 1 and save 2 precious bytes!
After some experimenting, col was eventually placed in the BSS as it’s better to not change the code if we really don’t have to.
Also, to kill a few birds with one stone, col was placed immediately before coords, so the Line-A setup code was transformed from:
linea #0 [ Init ]
movea.l A0,A5 ;pointer to linea variables
move.l #col,8(A5)
move.l #coords,12(A5)
to:
linea #0 [ Init ]
lea 8(A0),A0 ;pointer to linea colour
lea col(PC),A3
move.l A3,(A0)+ ;save colour
addq.l #2,A3 ;col+2=coords
move.l A3,(A0) ;save coords
Notice how we now switched to PC relative addresses for everything. So although the second snippets looks like it’s more code, in practice we use smaller opcodes, plus we avoid the “hidden” cost of having to emit reloaction information for col and coords in the first snippet. Also, a3 is now primed with the coordinates address, so we can modify the code that writes the coordinates in the inener loop from:
movem.w D2/D5,coords
to:
movem.w D2/D5,(a3)
Which means: even more gains in terms of instruction size and relocation!
Finally, we can gain an extra 2 bytes by modifying the coordinate clamping from:
andi.w #$7F,D2
andi.w #$7F,D5
to:
moveq #$7F,D0
and.w D0,D2
and.w D0,D5
Again, seemingly more instructions, but less size overall.
The apparent things to optimise were getting increasingly more difficult to spot. Top men from Newline (and the Innovator) were requested for comments, voluntarily of course.
May 29 2020, 21:38 - 282 bytes
Not a lot forward progress happened in the next few hours. Some register shuffling happened to bring x and y registers close (d4 and d5). The colour clamp code was changed from:
addq.w #1,col ;colour selector
andi.w #3,col
to:
addq.w #1,-2(A3) ;colour selector
andi.w #3,-2(A3)
so, two less relocations required and also smaller instructions.
Also, the call to Line-A was saving and restoring all registers. Ideally we would want to save and restore zero registers, but for now this was changed to save and restore only what was necessary. So this:
movem.l D0-A6,-(SP)
linea #1 [ Putpix ]
movem.l (SP)+,D0-A6
became this:
move.w D2,-(SP)
linea #1 [ Putpix ]
move.w (SP)+,D2
An obvious thing to look into was certainly the code that changes direction (from carry_clear to a bit below no_82). With some Self Modifying Code (SMC) we could perhaps remove those addq/subq commands and just have one that we modify depending on the two bits of d3. For reference, here are all the possible instruction opcodes we need:
addq.w #1,d4 = $5244
subq.w #1,d4 = $5344
addq.w #1,d5 = $5245
subq.w #1,d5 = $5345
So let’s give it a shot. For reference here is the normal code:
and.b #$82,D3
bne.s no_00
addq.w #1,D5
no_00:
cmp.b #$02,D3
bne.s no_02
addq.w #1,D4
no_02:
cmp.b #$80,D3
bne.s no_80
subq.w #1,D5
no_80:
cmp.b #$82,D3
bne.s no_82
subq.w #1,D4
no_82:
and here is the same code with SMC:
; bit 1 controls register (0=d5, 1=d4)
; bit 7 controls add/sub (0=add, 1=sub)
and.b #$82,D3
move.w #$5244,D0 ;load opcode assuming bits 1,7=0,0
btst #1,D3
bne.s our_reg_is_d4
or.w #$01,D0
our_reg_is_d4:
btst #7,D3
beq.s we_add
or.w #$0100,D0
we_add: move.w D0,smc
nop
smc: nop
The main idea behind the code is explained partially in the comments: Firstly we load one of the four opcodes, ideally the one that has the bits that control add/sub and select register d4/d5 unset. Then we test bits 1 and 7 of d3 and modify the opcode. Finally we write it to the place where it should execute.
There are a couple of weird things with this code though. We use a label to write the opcode instead of a PC relative address. That is wasteful and of course fixable.
But what about the two NOPs? Obviously the one in smc doesn’t matter because it will be overwritten before the program flow reaches smc. The second is a bit more tricky and has to do with the 68000 prefetcher. To put it simply: the prefetcher loads the next opcode to be executed while the current opcode is being processed. This way the CPU doesn’t have to stall waiting for the next instruction when it’s done with the current one.
The above means that if we omit that first NOP, then the first time the CPU reaches smc it will have prefetched the NOP and will execute that. The second time it reaches smc it will fetch the first write in the previous loop iteration. And so on. So, adding that NOP ensures that our opcode will be written by the time the CPU prefetches it.
How to get rid of that NOP? Well, just bring in an instruction that is executed after smc but doesn’t affect the program flow. How about that moveq #$7F,D0 we use for clamping? That will do nicely. Funnily enough, this takes the same amount of bytes as the original version, which was disasppointing.
But well, onwards and upwards.
May 29 2020, 22:47 - 276 bytes
Some register shuffling and optimising happened. Namely:
- In the original source d3 was being used as a copy of the seed which was being modified. But since the SMC version performs non destructive
btstinstructions, we can instead use the seed register (d6) directly. That frees d3. - Because of the above we can now use d3 as an inner loop counter instead of d2.
- Consequetively this means that we don’t have to save and restore any registers during the Line-A call, so 4 bytes less!
May 29 2020, 22:57 - 274 bytes
tIn spotted that the move.w d0,smc could be changed to move.w d0, smc-col(a3) - an extra 2 bytes saved!
May 29 2020, 23:19 - 266 bytes
Here’s where things took a dark turn.
As a reminder we’re using Line-A to draw pixels on screen. It just so happens that there’s quite a few other variables in the Line-A tables exposed.
Now, cast your mind back to Set screen buffer and resolution. One of the things we mentioned there was that we could get a nice clear screen buffer by starting our program as a .TOS file, but it would display an annoying blinking cursor. It turns out that we can control that cursor easily by poking Line-A register -$6: Cursorflag. So, if we add the following magic line of code:
sf -6(A0) ;kill cursor
after the Line-A init and rename our program to .TOS, the cursor goes poof, and with it 8 bytes (namely, the GEMDOS call used to clear the screen, plus the string printed).
May 29 2020, 23:33 - 264 bytes
By this point tIn was in a roll.
Let’s consider the code that loads the initial seed:
move.l #$7EC80000,D6 ;seed
moveq #63,D7
lea brush(PC),A6
outer_loop: move.w (A6)+,D6
It is apparent that what happens is that we load the upper 16 bits of d6 with the seed value, and then we load the first seed (etc) in the lower 16 bits. But in order to place the $7ec8 value at the top 16 bits we also waste 16 bits filled with zeros. So, instead of loading the seed value as a constant, why not kill two birds in one stone and move the seed value immediately above the brush values? That way we can rewrite the above code like this:
; The seed is now loaded as a part of brush_pre
; Originally the low part of the seed was loaded at the
; start of outer_loop but it has been moved to the end
; in order to consume the words properly
; since we load the first 2 words in 1 operation
moveq #63,D7
lea brush_pre(PC),A6
move.l (A6)+,D6
outer_loop:
And brush_pre is placed here:
brush_pre: DC.W $7EC8
brush: DC.W $030A,$37BE,$2F9B,$072B,$0E3C,$F59B,$8A91,$1B0B
...
Of course now we placed the load outside outer_loop so we have to compensate for this. We have to add the following line before we loop back to outer_loop:
move.w (A6)+,D6 ;load seed
dbra D7,outer_loop
Result: 2 bytes gained, in style!
May 29 2020, 23:54 - 262 bytes
Breaking tIn’s combo spree, some register shuffling produced an extra saving of 2 bytes.
May 29 2020, 23:56 - 260 bytes
A forgotten lea 8(A0),A0 converted to addq.l #8,A0 saved another pair of bytes.
May 30 2020, 00:10 - 258 bytes
Grasping at straws at this point and dangerously close to the finishing line. tIn realised that in the SMC part the and.w #$FFFE,D0 could be converted to subq.w #1,D0 since we just want to clear the lowest bit and our opcodes were guaranteed to not underflow ($5345->$5344 or $5245->$5244, i.e. the last digit was not 0 so it wasn’t going to alter the opcode if we subtracted one).
A stroke of genius brought us 2 bytes before 256.
May 30 2020, 00:18 - 256 bytes
Lastly, I had the honour of shaving off the last two bytes to bring the code size down to 256 bytes. Triggered by tIn’s finding I had another look at the SMC code and noticed this:
our_reg_is_d5:
btst #7,D6
beq.s we_add
Wait a minute, that btst instruction is 4 bytes, because the immediate #7 is not encoded in the opcode itself. So if we rewrite that code to:
move.b D6,D6
bpl.s we_add
then bingo, -2 bytes for a total of 256 bytes. (the branch had to be inverted because we now rely on the byte value being positive, i.e. we check the N flag in CCR)
And that’s it?
After some congratulatory banter between me and tIn, a ZIP file containing the release was sent to Dead Hacker Society to compete in Sommarhack 2020 256 byte compo at 00:39.
Last thoughts and tidbits
So that’s that. MonaST went on to be ranked #1 in the compo (alongside with SFMX’s DER SPKR IMPERATIV.
An interesting side effect of writing something that is fully system legal (well, almost. Atari never encouraged Line-A much or advised using it). When we tried it in different setups, it just worked. ST Low, St Medium, ST High (not quite correct colours but it’s visible), all check out. Then on TT, TT Low/Medium/High, all good. It also works on Falcon resolutions apart from High Colour ones where the poor thing crashes spectacularly.
Note that the optimisation originators are a bit approximate, as there were a lot of discussions between myself and tIn during those 6 hours of optimisation. Something one said might have made the other think of something, or perhaps not. No matter what, it was certainly a group effort.
Of course when we hit the magic 256 number we just stopped right there. There might be a couple of other optimisations to try (for example there are some questionable rewrites in the Line-A init that could yield a few bytes more). But frankly, we stopped caring at that point. If we wanted to bring the actual file size down to 256 bytes we’d have to chop off another 32 bytes, and really it didn’t seem that possible. Also, spending 7-8 hours of size optimising was more than enough for either of us, and we weren’t going to pick this up a later day. So: 256+32 it is.
Here is the final version of the source as it was submitted, again minus profanity (Turbo Assemnbler format, it should be trivial to port to other assemblers:
; Started 28th May 2020 around 21:00
; Almost worked the first time! (without size optimising)
; (it basically worked but line-a was clobbering the x coord, d'oh!)
; First "yes it works, shut up" version in 29th May 2020 17:25 - 302 bytes
; 294 bytes - 18:47
; 282 bytes - 21:38
; 276 bytes - 22:47
; 274 bytes - 22:57 (tin suggested smc-col(a3)!)
; 266 bytes - 23:19 (tin suggested .tos output + line-a to stop cursor blink)
; 264 bytes - 23:33 (tin suggested loading the constant using brush_pre)
; 262 bytes - 23:54
; 260 bytes - 23:56
; 258 bytes - 00:10 30th may (tin suggested subq instead of andi)
OUTPUT 'MONA.TOS'
dump EQU 0 ;save "dataset",.dataset,^a4
lowres EQU 0
>PART 'lowres'
IF lowres
clr.w -(SP)
move.l #-1,-(SP)
move.l (SP),-(SP)
move.w #5,-(SP)
trap #14
lea 12(SP),SP
ENDC
ENDPART
>PART 'dump'
IF dump
lea dataset,A4
ENDC
ENDPART
linea #0 [ Init ]
sf -6(A0) ;kill cursor
addq.l #8,A0 ;pointer to linea colour
lea col(PC),A3
move.l A3,(A0)+ ;save colour
lea 2(A3),A5 ;col+2=coords
move.l A5,(A0) ;save coords
pea pal(PC)
move.w #6,-(SP)
trap #14
; Who even adjusts the stack in 256 byte intros?
; The seed is now loaded as a part of brush_pre
; Originally the low part of the seed was loaded at the
; start of outer_loop but it has been moved to the end
; in order to consume the words properly
; since we load the first 2 words in 1 operation
moveq #63,D7
lea brush_pre(PC),A6
move.l (A6)+,D6
outer_loop:
move.b D6,D4 ;bx
move.w D6,D5
lsr.w #8,D5 ;by
addq.w #1,(A3) ;colour selector
andi.w #3,(A3)
move.w D7,D3
addq.w #1,D3
lsl.w #5,D3
subq.w #1,D3 ;inner loop counter
;d3=dir=assumed 0
inner_loop: add.l D6,D6 ;test seed for carry
bge.s carry_clear
eori.l #$04C11DB7,D6
; addq.w #1,d4 5244
; subq.w #1,d4 5344
; addq.w #1,d5 5245
; subq.w #1,d5 5345
; bit 1 controls register (0=d5, 1=d4)
; bit 7 controls add/sub (0=add, 1=sub)
move.w #$5245,D0 ;load opcode assuming bits 1,7=0,0
btst #1,D6
beq.s our_reg_is_d5
subq.w #1,D0
our_reg_is_d5:
; btst #7,D6
; beq.s we_add
move.b D6,D6
bpl.s we_add
or.w #$0100,D0
we_add: move.w D0,smc-coords(A5)
carry_clear:
; smc is after the moveq because prefetch baby!
; (i.e. writing the next instruciton the cpu fetches = bad news bears)
moveq #$7F,D0
smc: DC.W $5245 ;opcode assumes bits 1,7=0,0
and.w D0,D4
and.w D0,D5
movem.w D4-D5,(A5)
>PART 'dump'
IF dump
movem.w D4-D5,(A4)
move.l D6,4(A4)
addq.l #8,A4
ENDC
ENDPART
linea #1 [ Putpix ]
dbra D3,inner_loop
move.w (A6)+,D6 ;load seed
dbra D7,outer_loop
bra.s *-2
brush_pre: DC.W $7EC8
brush: DC.W $030A,$37BE,$2F9B,$072B,$0E3C,$F59B,$8A91,$1B0B
DC.W $0EBD,$9378,$B83E,$B05A,$70B5,$0280,$D0B1,$9CD2
DC.W $2093,$209C,$3D11,$26D6,$DF19,$97F5,$90A3,$A347
DC.W $8AF7,$0859,$29AD,$A32C,$7DFC,$0D7D,$D57A,$3051
DC.W $D431,$542B,$B242,$B114,$8A96,$2914,$B0F1,$532C
DC.W $0413,$0A09,$3EBB,$E916,$1877,$B8E2,$AC72,$80C7
DC.W $5240,$8D3C,$3EAF,$AD63,$1E14,$B23D,$238F,$C07B
DC.W $AF9D,$312E,$96CE,$25A7,$9E37,$2C44,$2BB9,$2139
pal: DC.W 0,$0F74,$0FC9,$0CA0 ;ste order (probably!)
BSS
DS.W 12 ;pad for the palette
; Line-A stuff
col: DS.W 1
coords: DS.W 2
>PART 'dump'
IF dump
dataset:
DS.L 65535
DS.L 65535
DS.L 65535
DS.L 65535
DS.L 65535
ENDC
ENDPART
END